
Praticamente tudo que uma pessoa faz na internet gera uma quantidade considerável de informação. Google, Facebook, X (antigo Twitter) e tantos outros, mantém rastros de todos os movimentos que fazemos. Não à toa, quando pesquisamos um produto, ou até mesmo conversamos com alguém, seja por texto ou até pessoalmente, as empresas começam a apresentar anúncios desse produto. E este é apenas um sintoma mais aparente . O que as empresas guardam é muito profundo e em quantidades enormes.
Uma quantidade tão grande de informação só é útil se poder ser consultada, analisada e gerar conhecimento. É aqui que entram os bancos de dados e as ferramentas de análise, permitindo que essa massa de dados seja organizada e utilizada para tomada de decisões estratégicas. Dentre esses recursos, destaca-se a linguagem SQL!
Meu primeiríssimo contato com SQL foi em meados do ano de 2009, na disciplina de Banco de Dados 1 do curso de Ciência da Computação. Coincidentemente, na mesma época entrei para um projeto de extensão dentro do próprio curso, vinculado ao departamento de informática da universidade. No projeto eu trabalhava junto com outros alunos do curso na construção de um sistema de gestão escolar. A professora da disciplina de banco de dados também participava do projeto, ela era a DBA. Este projeto, com certeza, direcionou minha vida profissional dali em diante.
Nas poucas oportunidades que tive de ensinar o básico de SQL para alguém, eu buscava fazer um jogo de palavras para tornar aquilo um pouco mais fácil de entender. Era algo como “SELECIONE as colunas DAS tabelas com esses FILTROS” (SELECT colunas FROM tabelas WHERE filtro). Pra mim, sempre soou estranho ter que primeiro indicar as colunas sem antes ter as tabelas das quais elas serão extraídas. Este comportamento estranho fica bem visível quando estamos usando um IDE para SQL: geralmente, ela não consegue auto completar os nomes das colunas antes de ter as tabelas indicadas na cláusula FROM. São detalhes.
Apesar do que eu acho, SQL é um incontestável padrão de mercado. Qualquer banco de dados relacional consegue interpretar um “SELECT * FROM tabela WHERE condição”. Embora cada sistema de banco de dados adicione recursos exclusivos de sintaxe e tipos de dados, existe um padrão para um conjunto menor de operações de consulta. O SQL foi inicialmente padronizado pela ANSI (American National Standards Institute) e ISO (International Organization for Standardization) na década de 1980. Desde então, diversas versões do padrão foram lançadas, incluindo SQL-86, SQL-89, SQL-92, SQL:1999, SQL:2003, SQL:2008, SQL:2011, SQL:2016 e SQL:2019.
A padronização, no entanto, não obriga que sistemas de banco de dados diferentes sejam compatíveis entre si. Um SQL escrito usando recursos do Oracle não é compatível com um MySQL, PostgreSQL, ou qualquer outro. A padronização funciona apenas como um guia para que exista um núcleo comum, incluindo a presença de SELECT, FROM, WHERE, GROUP BY, ORDER BY, integridade referencial, gerenciamento de transações (ACID), dentre outros recursos.
Tipos de dados, nomes desses dados e recursos de sintaxe podem variar. Uma consulta complexa pode ser muito verbosa e ter baixa expressividade, sobretudo em estrutura de tabelas muito normalizadas. A falta de padronização não é um problema complexo se considerarmos que uma consulta escrita para Oracle, por exemplo, não precisa rodar em um Google Big Query. Assim, este problema estaria mais relacionado à curva de aprendizado de recursos específicos de cada sistema.
O paradigma onde o SQL atua, o relacional, tem algumas diferenças sobre como as informações são transmitidas, seja via XML, JSON, texto, etc. Pela sua natureza, banco de dados relacionais são naturalmente projetados para escalar verticalmente, embora possam escalar horizontalmente. O modelo relacional, dependendo do nível de normalização, que trabalha com tabelas e colunas relacionadas entre si, acrescenta um nível de complicação extra no trabalho com linguagens orientadas a objetos, onde temos classes e objetos. Fazer o mapeamento é algo que pode ser sensível e o trabalho e muitas vezes é delegado para um ORM.
Google SQL
O artigo “SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL”, escrito por pesquisadores do Google, discute as limitações da linguagem SQL e propõe uma solução baseada em uma sintaxe de pipeline. O texto argumenta que, apesar do sucesso e onipresença do SQL, sua sintaxe rígida e complexa torna a linguagem difícil de aprender, escrever e manter. Alternativas ao SQL já foram propostas, mas nenhuma conseguiu substituí-lo devido à sua adoção massiva e ao custo elevado de migração. Em vez de criar uma nova linguagem, o Google optou por uma abordagem incremental, introduzindo operadores de pipeline na linguagem GoogleSQL. Essa nova sintaxe permite expressar consultas de forma mais intuitiva e legível, eliminando a necessidade de subconsultas excessivas e proporcionando uma experiência de desenvolvimento mais fluida.
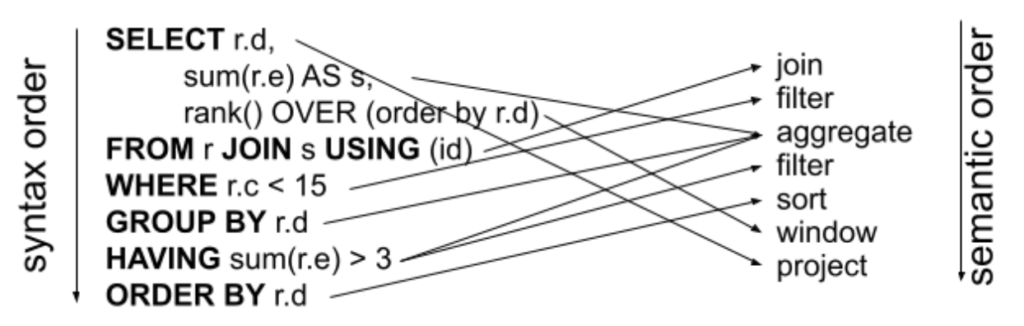
O GoogleSQL é um dialeto do SQL, isto é, desenvolvido a partir dos padrões ANSI do SQL, e é utilizado em seus sistemas internos de banco de dados, incluindo BigQuery, Spanner, F1 e Procella. Por ser baseado no padrão original do SQL, ele é compatível com consultas comuns, mas adiciona suporte a arrays, estruturas, JSON e otimização para consulta sobre grande quantidade de dados.
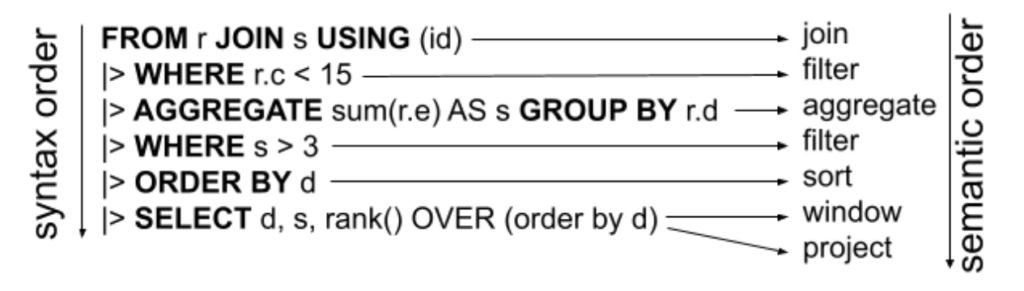
A nova sintaxe em pipeline funciona de maneira sequencial, permitindo que as operações sejam encadeadas e aplicadas de forma mais natural, semelhante ao que ocorre em APIs como Pandas e Apache Beam. O artigo apresenta comparações entre SQL tradicional e a versão com pipeline, demonstrando como a nova abordagem melhora a clareza e a extensibilidade da linguagem. Segundo o texto, os novos recursos tornam o SQL mais acessível, extensível e eficiente, facilitando tanto o aprendizado quanto o desenvolvimento, ao mesmo tempo que preserva seus fundamentos relacionais e a compatibilidade com sistemas existentes. Particularmente, mais uma vez, achei estranho ter que escrever um “|>”.
Cypher
A linguagem de consulta Cypher é a principal interface para interagir com bancos de dados Neo4j, que seguem o modelo de grafos. Ela é projetada para ser intuitiva e expressiva, permitindo consultas eficientes em grafos complexos. Aqui, os banco de dados de grafos são muito diferentes de banco de dados relacionais, tanto na natureza de como as informações são armazenadas, estruturadas e relacionadas, quanto na forma de consultar. Por isso, uma linguagem completamente diferente é necessário. Mas ainda assim, inspirada em SQL.
O Cypher começou como a linguagem de consulta exclusiva dos banco de dados Neo4j, mas ganhou relevância e acabou sendo adotado por outros bancos de dados de grafos. Em 2015, a Neo4j anunciou a iniciativa openCypher, tornando a linguagem aberta para a comunidade e permitindo que outros bancos de dados a adotassem. Embora o Cypher seja amplamente reconhecido na comunidade de bancos de grafos, ele ainda não é um padrão oficial, como o SQL. No entanto, ele é um dos principais concorrentes na padronização de consultas para grafos, competindo com linguagens como Gremlin (Apache TinkerPop – framework de computação para grafos e banco de dados de grafos) e GraphQL para banco de grafos.
Em 2018, uma outra linguagem, a Graph Query Language (GQL) foi oficialmente aprovada pela ISO para se tornar o primeiro padrão internacional para bancos de dados de grafos. O Cypher influenciou fortemente o desenvolvimento do GQL, e muitos de seus conceitos foram incorporados.
Não faz muito tempo que conheci o Neo4j e, com ele, a necesidade de trabalhar com Cypher. Achei a linguagem muito interessante. Imagine relacionamentos entre várias informações, como A -> B -> C -> D -> E, com qualquer quantidade de elementos, conexões, ciclos, etc (um grafo). A Cyper permite realizar consultas nessas estruturas que são impraticáveis de organizar e consultar em banco de dados relacionais.
Criando algumas “pessoas” em Cypher:
CREATE (alice:Person {name: "Alice", age: 25}),
(bob:Person {name: "Bob", age: 30}),
(charlie:Person {name: "Charlie", age: 35}),
(dave:Person {name: "Dave", age: 28})Relacionamentos entre elas:
- Alice conhece Bob
- Bob conhece Charlie
- Charlie conhece Dave.
MATCH (a:Person {name: "Alice"}), (b:Person {name: "Bob"})
CREATE (a)-[:KNOWS]->(b);
MATCH (b:Person {name: "Bob"}), (c:Person {name: "Charlie"})
CREATE (b)-[:KNOWS]->(c);
MATCH (c:Person {name: "Charlie"}), (d:Person {name: "Dave"})
CREATE (c)-[:KNOWS]->(d);
Exemplos de consultas:
-- Listar as pessoas
MATCH (p:Person)
RETURN p.name, p.age;
--
+--------------+
| p.name | p.age |
+--------------+
| Alice | 25 |
| Bob | 30 |
| Charlie | 35 |
| Dave | 28 |
+--------------+
-- Encontrar todas as pessoas que Alice conhece
MATCH (alice:Person {name: "Alice"})-[:KNOWS]->(friend)
RETURN friend.name;
--
+----------+
| friend.name |
+----------+
| Bob |
+----------+
-- Contar quantas amigos cada pessoa tem
MATCH (p:Person)-[:KNOWS]->(friend)
RETURN p.name, count(friend) AS num_amigos;
--
+--------------+
| p.name | num_amigos |
+--------------+
| Alice | 1 |
| Bob | 1 |
| Charlie | 1 |
+--------------+
Diferente do “|>” do GoogleSQL, o sinal “->” para indicar um relacionamento me parece bem mais natural. Depois de executarmos todas as operações necessárias para filtrar alguma informação util, a consulta encerra com um RETURN, conhecido de todo mundo. Depois de tanto trabalhar com SQL, o Cypher parece, e é, uma versão muito mais evoluída do SQL. Não poderia ser diferente, pois as necessidades em banco de dados grafos são outras. Mas é bastante curioso que mesmo depois de décadas, o SQL continue basicamente o mesmo, até nos sistema de banco de dados relacionais mais avançados. Embora cada um tenha sintaxe e outros recursos que buscam facilitar uma ou outra necessidade, o SQL sempre tem cara de SQL.


